
Alô galera! Iniciando hoje uma série de posts sobre Docker. Essa série contém tudo o que você precisa saber para entender o funcionamento dessa incrível ferramenta e começar a trabalhar na containerização e deploy de aplicações de forma simples, rápida e sem complicação.
Nesse post abordarei o funcionamento básico do docker e os recursos usados por ele.
Escrito em Go – linguagem de programação desenvolvida pela Google em parceria com a comunidade open source – o docker é definido como uma plataforma de código aberto utilizada para desenvolver, entregar e executar aplicações utilizando containers.
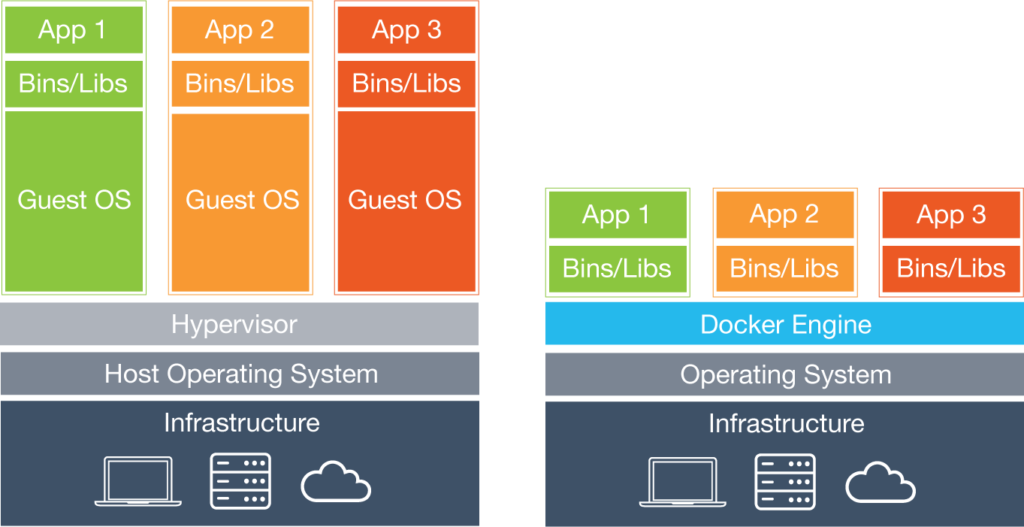
A containerização é um método de virtualização a nível de sistema operacional capaz de executar múltiplos sistemas de forma isolada. Diferente dos métodos tradicionais de virtualização a containerização compartilha o kernel do sistema operacional do host, dispensando o uso da camada de virtualização (hypervisor).
Pense em uma aplicação hospedada em uma máquina virtual do tipo bare-metal (VmWare Esxi, Hyper-V, etc) por exemplo. Sempre que algum processo dessa máquina precisa interagir com o hardware físico (escrever um arquivo no disco rígido por exemplo), essa “chamada” ao hardware será enviada (pelo sistema operacional convidado) à camada de virtualização que fará a interação com o hardware. Essa técnica acaba gerando uma carga extra na comunicação entre aplicação (máquina virtual) e o hardware físico.
A situação fica ainda pior se a virtualização for do tipo hosted (Virtualbox, VmWare Player, etc.), visto que entre a camada de virtualização e o hardware físico existe ainda a camada do sistema operacional do host.
A ausência da camada de virtualização no método de containerização, permite que os processos acessem os recursos de hardware diretamente através do kernel do sistema operacional do host, o que permite um uso de hardware mais eficiente.
A figura abaixo ilustra os dois métodos.
www.docker.com
O compartilhamento do kernel no método de containerização, exige que os sistemas sejam executados de forma isolada uns dos outros. Esse isolamento é feito usando um recurso do kernel linux chamado namespace, capaz de isolar recursos como PID, hostname, network, etc. de um grupo de processos.
De modo geral, o isolamento associa namespaces para cada grupo de processos, de modo que tais processos consigam acessar apenas os recursos associados ao mesmo namespace. Em outras palavras, o docker usa esse recurso para criar grupos de processos isolados (containers) para cada aplicação.
Além do namespaces, o docker utiliza cgroups para controlar o uso dos recursos de hardware, visto que os containers (assim como as máquinas virtuais) compartilham esses mesmos recursos. O cgroups (ou control groups) permite limitar e priorizar os recursos físicos de um host (CPU, memória, E/S de disco, etc.). O docker usa esse recurso tanto para limitar a quantidade de memória utilizada quanto para definir prioridades de uso de cpu para cada container, o que garante que a capacidade de um container esgotar os recursos de hardware, e como consequência “derrubar” o sistema do host, seja eliminada.
Uma das vantagens da containerização é que esse método não precisa virtualizar um sistema operacional completo (Guest OS) para executar as aplicações. Ao invés disso a aplicação é executada através de um container que é iniciado como um processo, tornando sua inicialização mais rápida do que em uma máquina virtual tradicional, que precisa passar por todo o processo de boot do sistema operacional virtualizado.
A ausência de um SO completo também implica na redução da quantidade de recursos de hardware utilizado por um container, como por exemplo espaço em disco (visto que um container é significativamente menor do que uma VM) e uso de memória RAM, pois apenas os processos necessários para executar a aplicação precisam ser carregados na memória.
Outra vantagem é que containers não dependem de hardware ou plataforma, logo podem ser executados em qualquer lugar, seja em um notebook, servidor físico ou virtual, em um datacenter ou na nuvem.
A arquitetura do Docker
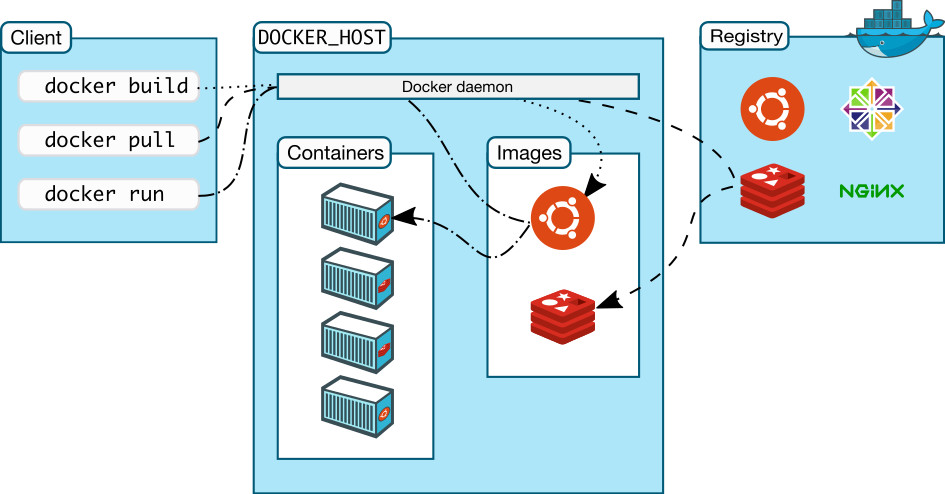
O docker utiliza uma arquitetura cliente-servidor básica formada por dois componentes principais: uma plataforma de containerização (docker engine) e um serviço de registro.
Veremos o serviço de registro em detalhes mais à frente. Por hora basta saber que esse é o serviço responsável pelo armazenamento de imagens.
A instalação do docker engine implementa tanto o cliente (docker client) quanto o daemon (docker daemon).
O cliente é a parte da estrutura responsável pela interface entre o usuário e o restante do sistema. É ele quem recebe os comandos do usuário, como por exemplo criar um container, baixar uma imagem, etc, e os envia ao daemon. O docker engine implementa um cliente em linha de comando na forma do comando docker.
O daemon por sua vez é responsável por receber e processar os comandos passados pelo cliente, interagindo com outros serviços (drivers) e fornecendo o que lhe foi solicitado, como criação de containers, manipulação de imagens, gerenciamento de recursos de rede, interface com o serviço de registro, e etc.
O gerenciamento da plataforma como um todo é feito pelo daemon com o auxílio de drivers. A ideia de driver aqui é a mesma de um driver de dispositivo em um computador ou servidor. Eles permitem que o sistema operacional faça uso do computador, gerenciando cada um o seu componente específico. No docker, os drivers são responsáveis por gerenciar recursos adicionais que fornecem serviços ao daemon (armazenamento, rede, etc), necessários para o pleno funcionamento da plataforma.
A imagem abaixo ilustra a arquitetura usada pelo docker:
www.docker.com
Quando instalado, o docker engine configura tanto o cliente quanto o daemon no mesmo sistema, o que permite que cada máquina em uma rede (ou isoladamente) possa executar sua própria plataforma de containerização. No entanto é possível utilizar cliente e daemon separadamente, por exemplo centralizando o daemon em um servidor na rede e instruindo os clientes nos desktops a se comunicarem com esse servidor.
A comunicação entre cliente e daemon é feita via socket por padrão. Um socket é um mecanismo que garante a comunicação bidirecional entre processos, estejam eles no mesmo sistema ou em sistemas remotos. O daemon docker pode utilizar três tipos de socket: unix, fd e tcp.
No momento da instalação do docker, o daemon cria por padrão um socket de domínio unix (unix:///var/run/docker.sock) ou um socket de ativação do systemd (fd://) – dependendo da distribuição do sistema operacional. Esses sockets são do tipo IPC (Inter-process comunication) e, como o nome sugere, garantem a comunicação entre cliente e daemon instalados no mesmo sistema.
Para que um cliente seja capaz de se comunicar com o daemon remotamente, o socket de rede tcp deverá ser utilizado. Esse método usa um endereço de socket representado pelo conjunto ip:porta (tcp://0.0.0.0:<porta>). É preciso considerar no entanto, que a comunicação via socket tcp não é criptografada por padrão, o que poderá ser corrigido configurando criptografia TLS (veremos na prática).
Recursos do docker
O funcionamento do docker é baseado em três recursos principais: imagem, container, e registro. Vamos entender como cada um desses recursos é composto e como eles funcionam.
Uma imagem docker é basicamente um pacote que pode conter um sistema operacional, um serviço, uma aplicação, etc. Por exemplo, uma imagem docker do wordpress contém um sistema operacional (debian, ubuntu, centos, etc), um servidor web (apache, nginx, etc) e a aplicação propriamente dita (wordpress). Lembre-se que o sistema operacional aqui não é um sistema completo, uma vez que o método de virtualização compartilha o kernel do host.
Imagens docker são compostas por camadas, empilhadas sobre uma camada base – normalmente correspondente ao sistema operacional. A figura abaixo ilustra as camadas que compõem uma imagem docker do ubuntu.

www.docker.com
Cada camada adjacente a camada base corresponde a uma instrução definida no momento da criação da imagem (veremos criação de imagens mais adiante). Essas instruções vão desde a inclusão/exclusão de um arquivo ou diretório até a instalação de um pacote ou serviço, incluindo a definição de uma imagem base, variáveis de ambiente, comandos, dentre outras configurações.
O docker utiliza ainda, um método de endereçamento de armazenamento de conteúdo baseado em criptografia hash, atribuindo um identificador único e seguro a cada camada de dados no disco.
Vale ressaltar que o tamanho de cada camada varia de acordo com a instrução que a criou. Por exemplo, uma camada que define uma variável será menor do que uma camada onde foi realizada a instalação de um pacote.
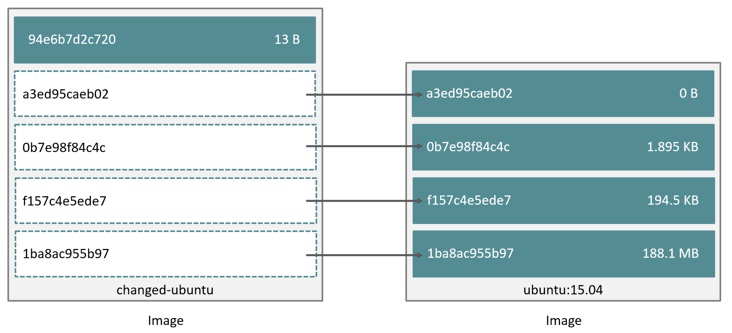
O sistema de camadas apresenta duas vantagens principais. A primeira é que qualquer alteração feita em uma imagem – seja a atualização de um componente/serviço, inclusão de arquivo, etc – resulta na criação de uma nova camada que será adicionada ao topo da pilha (imagem). O que garante que o processo de distribuição de uma atualização seja significativamente mais rápido e simples do que em uma máquina virtual tradicional (se um servidor já possui a imagem, ele irá baixar apenas a camada referente a atualização).
Outra vantagem é que o docker pode compartilhar camadas comuns entre duas imagens distintas. Voltando ao exemplo anterior, imagine que faremos uma alteração em uma imagem do ubuntu adicionando um arquivo de texto ou instalando um pacote nessa imagem. Como dissemos anteriormente, uma nova camada será adicionada ao topo da pilha, porém as camadas subjacentes serão compartilhadas entre a imagem original e a nova.
A figura abaixo ilustra as duas vantagens supracitadas.
www.docker.com
A nível de recursos de hardware, a combinação das duas técnicas garante uma redução no espaço em disco utilizado para armazenar as imagens. Isso porque, para o sistema operacional do host, cada camada é um arquivo. Logo o sistema de arquivos do host não precisa duplicar todas as camadas comuns entre imagens. Tomando por base o exemplo da figura acima, se analisarmos o diretório de armazenamento de camadas no host, encontraremos principalmente seis arquivos, cinco deles correspondendo às camadas da imagem original do ubuntu e um correspondendo a camada da imagem alterada.
Nesse ponto, a pergunta que deve ser feita é: se para o sistema de arquivos do host uma imagem docker é um conjunto de arquivos, como o docker consegue apresentar a imagem como um bloco único? Para isso o docker faz uso do sistema de arquivos unificado – ou unionfs. Esse serviço implementa uma montagem unificada, permitindo que arquivos e diretórios em locais distintos sejam apresentados como um único item.
O docker utiliza o sistema de arquivos unificado como driver de armazenamento. Apesar de suportar vários tipos de drivers como zfs, overlayfs, btrfs e devicemapper, o docker usa por padrão o aufs – implementação mais sofisticada do unionfs – que é responsável por todo o gerenciamento de armazenamento de dados como criação de camadas, montagem unificada e estratégia de cópia, além de implementar melhorias como balanceamento de escrita, dentre outras.
O registro, como vimos anteriormente, é o serviço de armazenamento das imagens. Ele é o componente de distribuição do docker, visto que as imagens são armazenadas em um ponto central, de onde é possível baixá-las e para onde é possível enviá-las.
O serviço de registro padrão fornecido pela Docker é o Docker Hub – que conta atualmente com mais de 100 mil imagens – porém é possível utilizar outros serviços como Google Cloud Plataform ou Amazon EC2 Container Registry. Além disso é possível construir um registro dentro da sua própria infraestrutura.
O registro pode fornecer um serviço de armazenamento público ou privado. Um armazenamento público permite que qualquer pessoa possa baixar e utilizar as imagens armazenadas. Isso significa que você poderá utilizar imagens criadas por outros usuários e ainda compartilhar suas próprias imagens com outros. Um armazenamento privado, por sua vez, restringe o acesso às imagens apenas aos usuários que possuam as credenciais para acessá-lo.
O Hub fornece os dois tipos de armazenamento.
A estrutura de armazenamento de um registro segue basicamente o modelo registro/repositório:tag.
Caso nenhum registro seja fornecido ao se utilizar o cliente docker para baixar ou enviar uma imagem, o registro será o docker.io, já que o serviço de registro padrão do docker é o Hub. Caso um registro local seja utilizado, será necessário informar ao daemon o nome do registro e, se necessário, a porta (registro.domínio:porta).
Por se tratar de um serviço público (compartilhado por vários usuários), o Hub organiza sua estrutura criando namespaces para cada usuário. Isso significa que quando você cria sua conta no Hub (http://hub.docker.com) você está criando um namespace que poderá ser usado para armazenar imagens, criar repositório e etc.
Esse modelo de organização separa imagens não oficiais de imagens oficiais – que são construídas e distribuidas pelos próprios mantenedores como debian, ubuntu, nginx, redis, mysql, etc. O armazenamento de uma imagem oficial é feito na raiz do registro (dispensando o uso de namespace), enquanto que uma imagem não oficial será armazenada no namespace do usuário que a criou (cmotta2016/ubuntu).
O segundo componente do modelo é o repositório, que representa a imagem propriamente dita – ambos os termos (repositório e imagem) são usados de forma intercambiável. É aqui que a definição de armazenamento público e privado é feita. Isso permite que em uma mesma conta (namespace) do Hub, você possar definir imagens que serão compartilhadas (público) e imagens que serão de uso exclusivo (privado).
Um repositório pode representar apenas uma imagem ou um conjunto de imagens essencialmente iguais mas em versões diferentes. Ou seja, um repositório do debian, por exemplo, pode conter as imagens das versões 6, 7, 8, etc.
A Tag é o componente que recebe um valor numérico (normalmente) para identificar a versão da aplicação contida na imagem ou a versão da compilação da própria imagem. Por exemplo, o repositório da imagem docker do ubuntu pode conter as tags 15.04, 15.10 e 16.04, o que representaria as versões do ubuntu dentro da imagem. Do outro lado, você pode definir tags para as imagens de uma aplicação proprietária, que recebe atualizações da equipe de desenvolvimento, para definir a versão da imagem (0.1.10, 0.1.20, etc.). Apesar da atribuição majoritariamente numérica, uma tag também pode ser definida como strings, como por exemplo imagens do debian podem receber tags do tipo jessie, wheezy, stable, etc.
Tags são normalmente definidas no momento da criação de uma imagem, mas também é possível alterar a tag de uma imagem a qualquer momento. Se uma tag não for definida (tanto na criação quanto na busca de uma imagem) o docker utiliza o valor padrão latest.
Vejamos abaixo alguns exemplos de busca de imagens:
debian – repositório oficial – última versão (latest) da imagem debian. Caminho completo usado pelo docker: docker.io/library/debian:latest
cmotta2016/myapp – repositório não oficial – última versão (latest) da aplicação proprietária (myapp) na conta (namespace) cmotta2016. Caminho completo usado pelo docker: docker.io/library/cmotta2016/myapp:latest
registro.domínio/sysadmin/apache:2.4 – registro local – versão 2.4 do apache no repositório sysadmin da organização. Esse já é o caminho completo usado pelo docker já que o registro foi especificado (por se tratar de um registro diferente do hub).
O terceiro recurso do docker que abordaremos é o container.
Identificado como o componente de execução do docker, um container é um espaço de trabalho onde uma aplicação (ou serviço) é executada(o). É basicamente o recurso que “roda” a aplicação, juntamente com todos os binários e bibliotecas necessária(o)s para torná-la disponível aos usuários.
Um container não hospeda a aplicação, logo ele precisa ser criado a partir de uma imagem onde a aplicação foi construída, conhecida como imagem base. É a imagem base que define os comandos a serem executados, portas a serem mapeadas, além de outras configurações utilizadas pelo container. De modo geral, o container possibilita a interação com os recursos da imagem.
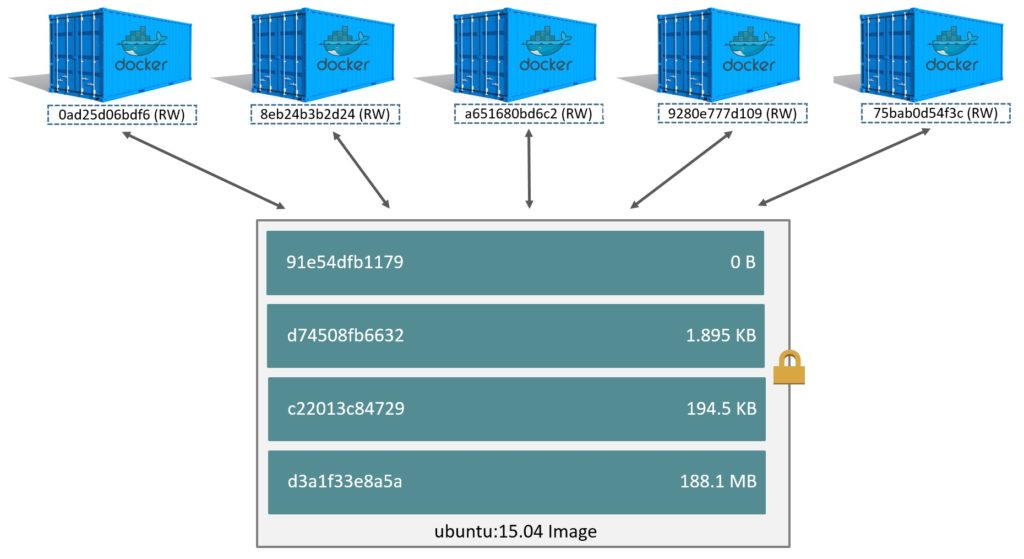
Vimos anteriormente que uma imagem é uma pilha de camadas arranjadas sobre uma camada base. A criação de containers segue o mesmo modelo, ou seja, o docker cria uma camada para cada container, adicionando essa camada ao topo da pilha correspondente a imagem base. De modo semelhante a imagem, cada camada de container recebe um identificador único em hash.
A grande vantagem aqui é que, graças ao driver de armazenamento usado no docker, apenas a camada do container é gravável, enquanto que as camadas subjacentes (que compõem a imagem) têm acesso apenas de leitura.
Isso significa que toda alteração feita em um container é armazenada em sua própria camada, enquanto que os dados armazenados na imagem permanecem inalterados, permitindo que múltiplos containers (criados a partir da mesma imagem base) possuam ao mesmo tempo dados comuns entre si (hospedados na imagem) e seus próprios dados modificados.
Graças a essa técnica, o docker permite que vários containers sejam executados sobre uma mesma imagem base. Repare na imagem abaixo:
www.docker.com
Uma forma bastante simples de entender é pensar na imagem base como um navio carregando vários containers. Cada container terá seu próprio conteúdo (movéis, alimentos, veículos), enquanto compartilham o mesmo meio de transporte, sem que o conteúdo dos containers alterem a estrutura do navio.
A técnica fundamental usada na manipulação de dados nesse cenário é a estratégia de compartilhamento e cópia (copy-on-write), implementada pelo sistema de arquivos unificado. Nessa estratégia, um dados (arquivo ou diretório) é compartilhado entre processos distintos que precisam acessá-lo. Quando um determinado processo precisa alterar o conteúdo desse dado, apenas o processo em questão fará uma cópia do dado para ser modificado.
Os passos realizados pela estratégia variam de acordo com o driver de armazenamento utilizado.
O driver padrão do docker (AUFS) inicia o processo buscando o arquivo a ser modificado. Essa busca é feita na pilha de camadas da imagem, da mais alta para a mais baixa (top-down). Ao encontrar o arquivo o driver copia esse arquivo para a camada do container (essa operação é chamada de copy-up), onde o mesmo poderá ser manipulado. Vale ressaltar que essa cópia será afeita apenas na primeira vez, ou seja, o arquivo copiado será mantido na camada do container para modificações futuras.
Se um determinado container precisar deletar um arquivo, o AuFS fará uso de um whiteout file. Um whiteout file é um arquivo, criado na camada do container, usado para “ocultar” a existência do arquivo original nas camadas subjacentes. Imagine por exemplo que um determinado processo no container removeu o arquivo file3 que pertence a imagem. O driver de armazenamento cria na camada do container um arquivo chamado .wh.file3 que informa aos processos do container que o arquivo em questão foi “deletado”. Esse exemplo é ilustrado na figura abaixo.
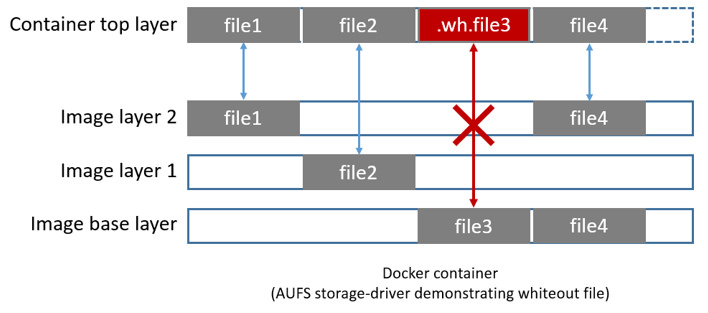
www.docker.com
Uma última consideração é que a camada correspondente a um container não é persistente. Isso significa que quando um container é deletado, sua camada correspondente também é removida, resultando na perda de toda e qualquer alteração feita em um container.
Existem duas formas do docker preservar dados de um container. Criando uma imagem a partir de um container (veremos mais a frente), ou exportando um volume de dados. A diferença entre essas duas técnicas é que a primeira permite que toda alteração feita no container (instalação de pacote, definição de variável, configurações nos processos, etc) se torne permanente (na forma de uma nova imagem). A segunda, por sua vez, preserva apenas alterações a nível de sistema de arquivos (criação/alteração de arquivos ou diretório dentro do container).
Um volume de dados é um arquivo ou diretório no filesystem do host que é montado diretamente no container, fazendo com que toda alteração feita pelo container seja consolidada diretamente no host. A grosso modo, é como se um computador mapeasse uma unidade de rede de um determinado servidor de arquivo, no diretório pessoa de um usuário. Mesmo que essa máquina seja perdida ou retirada da rede, os dados do usuário permanecerão disponíveis no servidor de arquivo.
O volume é definido no momento da criação do container podendo ser especificado o diretório/arquivo do host mais o do container, ou apenas o do container. Ambos os métodos garantem que o conteúdo do diretório não seja deletado ao remove o container por padrão. No entanto, se especificarmos somente o diretório do container, ainda será possível remover o volume juntamente com o container, passando uma opção específica ao daemon, o que não acontece no primeiro método (especificando o diretório do host mais diretório do container).
Isso acontece porque quando especificamos apenas o diretório do container, o driver de armazenamento cria um sub-diretório no path padrão do docker (/var/lib/docker/volumes) e assume o controle desse diretório. Dessa forma, quando passamos a opção para remover os volumes de dados juntamente com um container, o driver consegue deletar esse sub-diretório juntamente com todo o seu conteúdo. Esse comportamento faz com que o método de exportar volumes especificando tanto o diretório do host quanto do container seja o mais indicado.
O uso de volume de dados garante a persistência dos dados, mas também pode ser usado para compartilhar conteúdos entre containers. A figura abaixo ilustra dois containers compartilhando um volume de dados, definido no diretório data (criado no host).
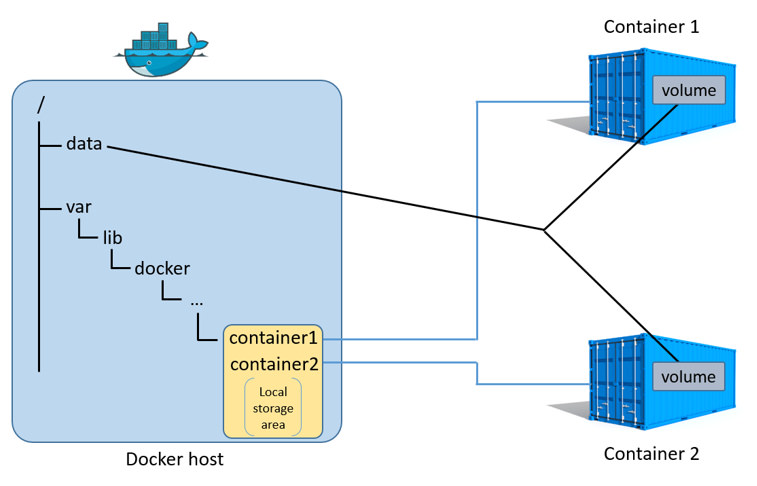
www.docker.com
Agora que conhecemos a arquitetura e os recursos principais do docker, podemos definir os passos tomados pelo docker engine quando da criação de um container.
- O cliente envia ao daemon o comando para criar um container, definindo qual imagem base será utilizada;
- O daemon verifica se a imagem passada já se encontra no host. Caso contrário ele busca a imagem no registro especificado pelo cliente (por padrão o docker Hub) e inicia o processo de download;
- Com a imagem baixada, o docker cria o container;
- No momento da criação do container o daemon invoca o driver de armazenamento para criar um diretório correspondente a camada do container, e montá-lo com permissão de escrita;
- Em seguida o daemon usa o driver de redes para alocar uma interface e atribuir um ip ao container (o gerenciamento de redes será abordado nos próximos posts);
- Executa o comando definido pelo cliente ou pela imagem (roda a aplicação);
- Por fim, exibe a saída gerada pelo processo.
Bom pessoal, por enquanto é só. Nos próximos posts abordaremos criação de imagens (automatizada e a partir de containers), gerenciamento de redes, cluster, e outras funcionalidades do docker. Deixe seu comentário ou sugestão e até mais!
Muito bom o post! Aguardando o restante…
Obrigado Filipi. Segue aí o segundo post https://www.mundotibrasil.com.br/docker-da-teoria-ao-hands-no-gerenciamento-de-redes/.
Legal a matéria! Sugiro que dê uma olhada no artigo abaixo, pode ajudar a complementar o que você escreveu.
https://azure.microsoft.com/en-us/blog/containers-docker-windows-and-trends/
Obrigado amigo. Já tinha visto esse post do Mark, muito legal.
Excelente post! Já vou ler o segundo! :D
Muito bom, mesmo excelente!!! Só senti falta da existência de alguma desvantagem, por exemplo, O I/O é melhor ou pior em relação a virtualização.